2023年12月6日(米国時間)Googleによって生成AIの新たなモデル「Gemini」の最初のバージョンであるGemini1.0がリリースされました。Geminiはテキストに加え、画像や動画を扱えるマルチモーダルなモデルであること、ベンチマークテストでも高評価を獲得していることからその性能の高さに注目が集まっています。
この記事では、Googleによる現時点(2023年12月現在)の発表情報をまとめ、Geminiの特徴を解説しています。Geminiで何ができるのか、これまでのモデルより何が優れているのかをわかりやすく紹介していますので、ぜひ最後までお読みください。
Geminiとは?Google提供の最新生成AIモデル
Geminiとは、Google Deepmind(GoogleのAI研究部門)、Google Research(Googleのコンピュータサイエンス研究部門)をはじめとするGoogle内の共同チームによって開発された、生成AIの最新モデルです。そんなGeminiの特徴は、以下のような点にあると言えます。
- マルチモーダルなモデルであること
- 幅広いプラットフォームをサポートする3つのモデルサイズを選択できること
- ベンチマークにおいて非常に好成績を記録していること
マルチモーダルなモデル
Geminiは、マルチモーダル(テキストだけでなく、動画や画像、音声など様々な種類のデータを入力、出力として扱えること)なモデルです。動画が得意なモデル、音声が得意なモデルといった個々に特化したモデルを組み合わせるのではなく、最初から複数のデータ形式を扱えるように開発されていることが特徴です。そのため、テキストや音声、画像といった異なる種類の情報を同時に受け取り、シームレスかつ自然に処理を行うことができます。
例えばGeminiでは入力された音声はテキストに変換して処理されるのではなく、音声データのまま処理されます。そのため、音声に含まれるニュアンスや抑揚といった要素も捉えることができます。
また、動画データに関してはフレームを等間隔でサンプリングすることで処理されますが、この時、フレーム間の前後関係(時系列)を理解し、動画の流れを考慮した結果を生成することができます。
これらの機能の実証として、人間がサッカーボールを蹴る動画を見てシュートまでの体の動きを時系列に理解したうえで、フォームを改善するためのアドバイスをする、といったタスクを行えることがGoogleの技術レポートによって示されています。
3つのモデルサイズ
Geminiは幅広いアプリケーションや実行環境で利用されることが想定されており、プラットフォームに合わせて3つのモデルサイズで提供されます。そのため、大規模なコンピュートリソースから、スマートフォンのような省電力を重視したデバイス上まで様々な環境で動作することが可能です。
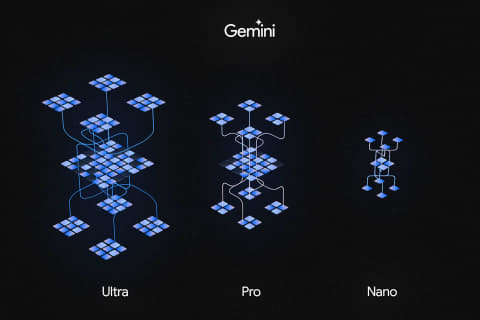
| Gemini Ultra | 非常に複雑で幅広いタスクに対して最も高いパフォーマンスを提供する、Gemini最大のモデルです。 |
| Gemini Pro | 強力なパフォーマンスを維持しつつ、コストやレイテンシがバランスよく最適化された、中規模のモデルです。 |
| Gemini Nano | デバイス上で実行用に設計された、最も効率的なモデルです。低メモリデバイス用にNano-1(18億パラメータ)、高メモリデバイス用にNano-2(32.5億パラメータ)が提供されます。 |
Geminiの今後の展開については後述しますが、特にGemini Proについては、Googleのコンシューマー向け生成AIサービスであるBardに既に導入されており(英語版のみ)、Google CloudのAI開発プラットフォームであるVertex AIでも生成AIの基盤モデルとして導入が予定されているなど、今後のメインストリームとなる予定です。
最高水準のベンチマーク
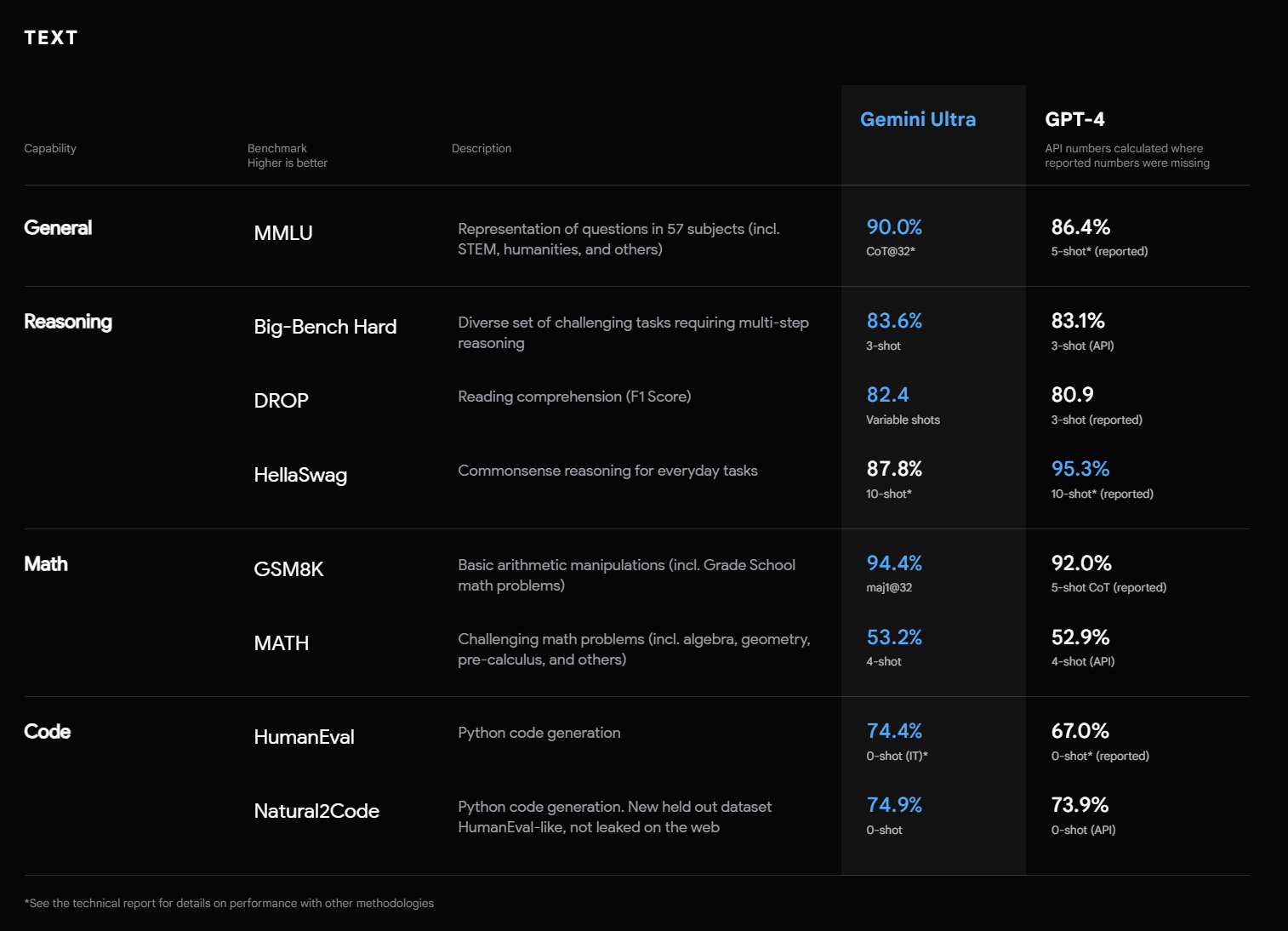
Gemini Ultraを用いてGoogleが行った32種類のベンチマークのうち、Geminiは30種類で既存の最高水準を上回る結果を記録しました。
特にMMLU(数学や法律など57科目において、一連のテキスト試験を通して知識と推論能力をテストするベンチマーク)では90%以上のスコアを達成しています。これは、各分野の専門家を上回るパフォーマンスを表しており、これほどのパフォーマンスを記録したモデルは初です。
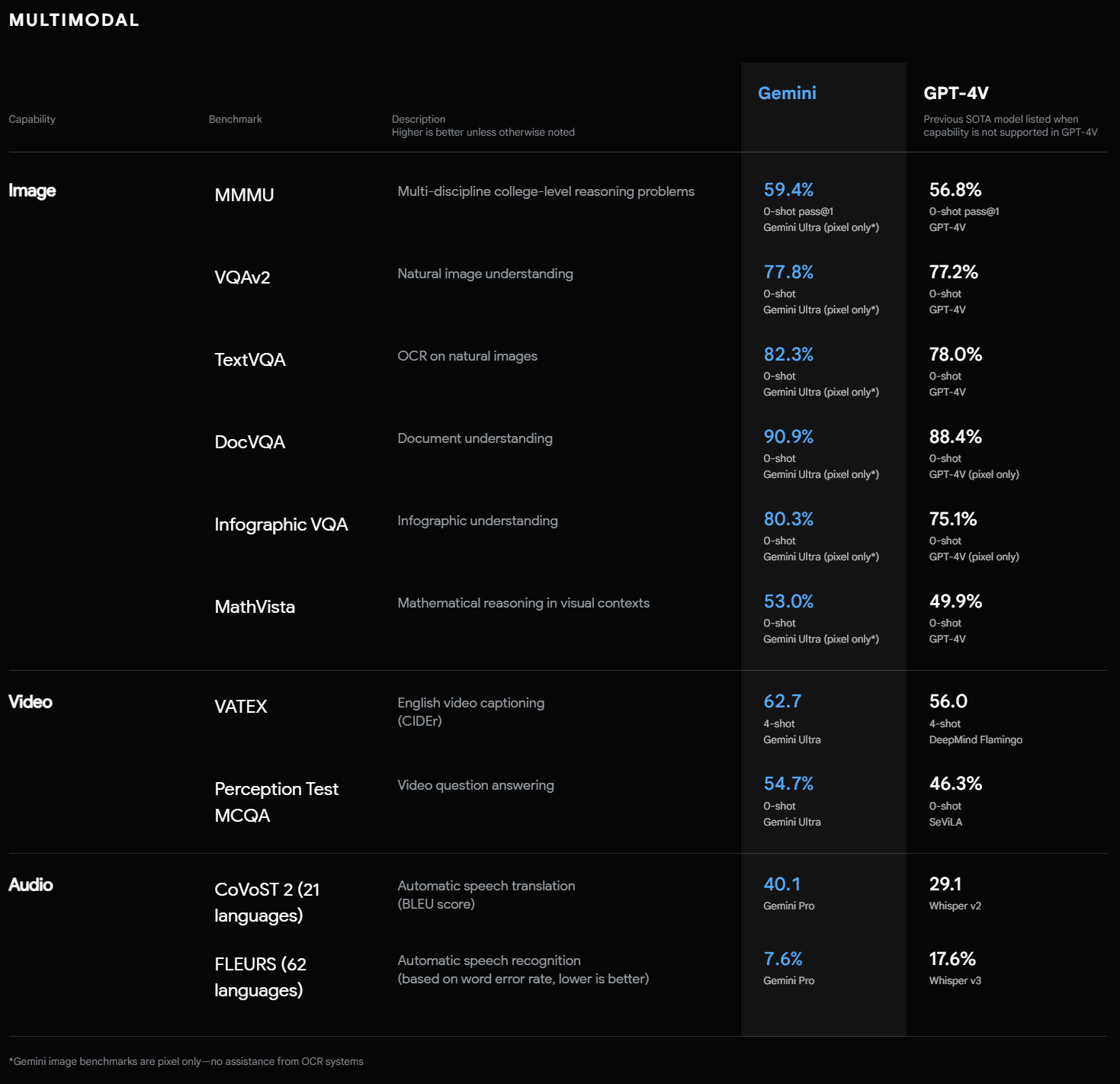
また、MMMU(複数の分野において大学レベルの知識が必要とされるテスト。テストには画像が含まれ、マルチモーダル性能の高さがテストされるベンチマーク)でも59.4%と最高水準のスコアを記録しており、Geminiがテキスト以外の入力に対しても高い性能を発揮できることが示されています。
Googleの技術レポートでは、人間の物理学テストの回答用紙を読み取ったGeminiが、手書きの数式や図を理解し、問題を解く手順や、回答の誤りを検証できることが示されており、ベンチマークスコアの高さを裏付けています。
以下は、Googleが発表しているGeminiでのベンチマークのスコアです。テキストだけでなく、動画、画像、音声といった分野に関しても最高水準の結果を記録しており、特にOpenAI社のGPT-4と比較しても、多くのテストで優れた成績を記録しています。
Geminiが得意なこと・できること
ここまでに解説したように、Geminiはネイティブにマルチモーダル対応し、テキストに限らず画像、音声、動画を組み合わせたデータ処理に対して非常に高い能力を持っています。では、実際にどのようなタスクをこなすことができるのか、Googleの公式情報からいくつか紹介します。
動画内のオブジェクトや環境変化を認識して、適切な応答をする
以下の動画では、画像とテキスト入力に対するGeminiの能力テストの様子が紹介されています。
テスト担当者はGeminiとやり取りをしながらイラストを描いたり、ゲームをしたりといったといった、複雑なタスクをいくつか行っています。
Geminiは、テスト担当者が線を書き加えていく過程を見ながら、それがアヒルの絵だと推測しました。



カップ&ボールのゲームでは、人間の手の動きを時系列に処理できており、ボールがどのカップに入っているかを言い当てています。

また、画面に映っている世界地図から国当てゲームを提案するなど、創造的な提案をしている様子も見られます。
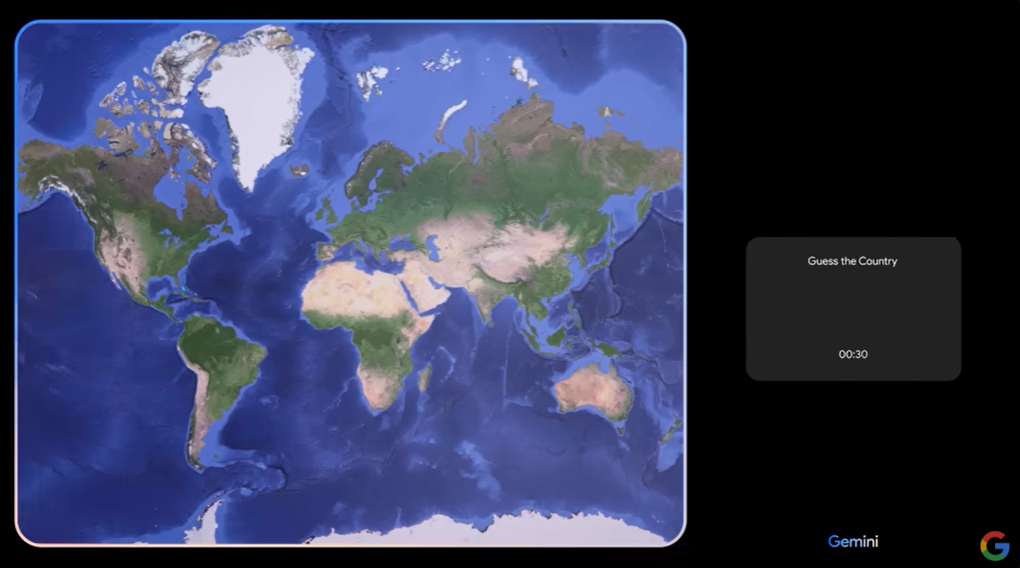
このように、動画や画像といったテキスト以外のデータを高度に認識し、それをもとにした推論や環境の理解ができることが明らかになっています。
Googleの技術レポートによると他にも、撮影した写真に映っているオブジェクトから撮影場所を特定するといったタスクも可能だとされており、Geminiが画像の周辺環境まで高度に理解できることが示されています。
詳しくは動画をご確認ください。
Hands-on with Gemini: Interacting with multimodal AI
記述式テストの正誤判定と、解答の解説
以下の動画では、物理学のペーパーテストに書かれた人間の回答に対して、Geminiが正誤判定はもちろん、間違った数式の解説や、復習のための練習問題生成といったタスクを行っている様子が紹介されています。注目すべきは、画像処理と推論の正確さです。図や手書きの数式が含まれるテスト問題にも関わらず、4つの設問と問題の意図を正確に認識することができています。
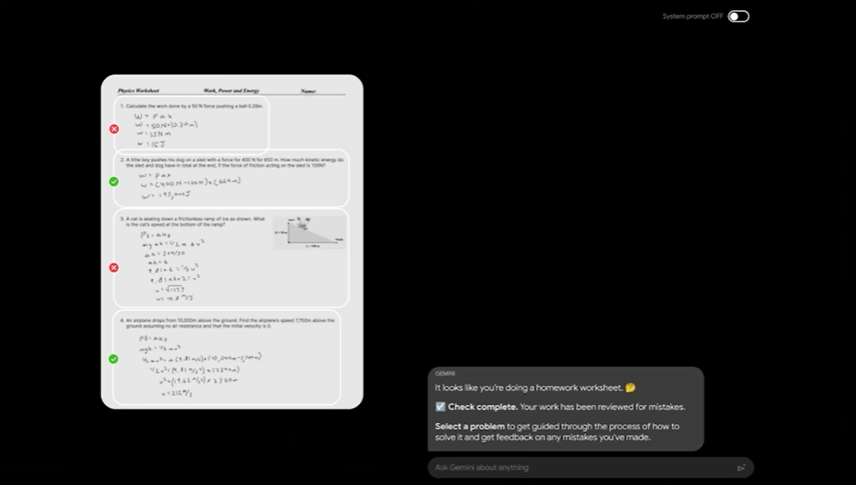
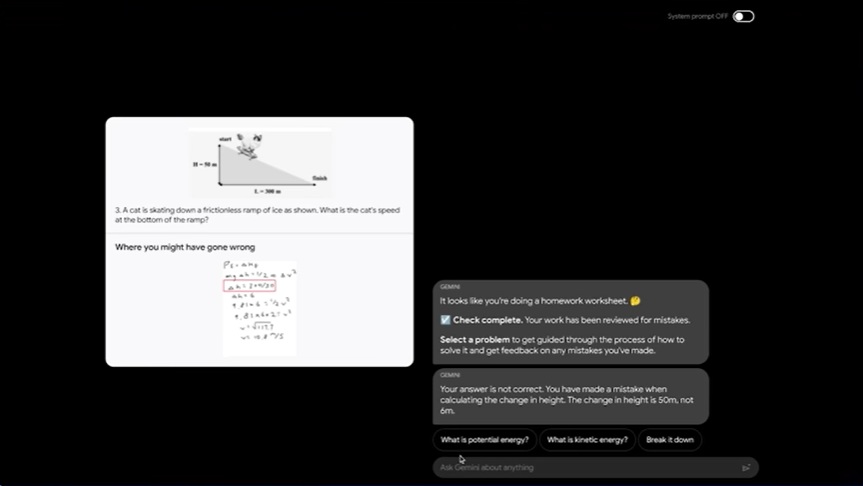
また、図が何を表しているかも正確に理解し、似たような練習問題を新たに生成する様子も見られます。
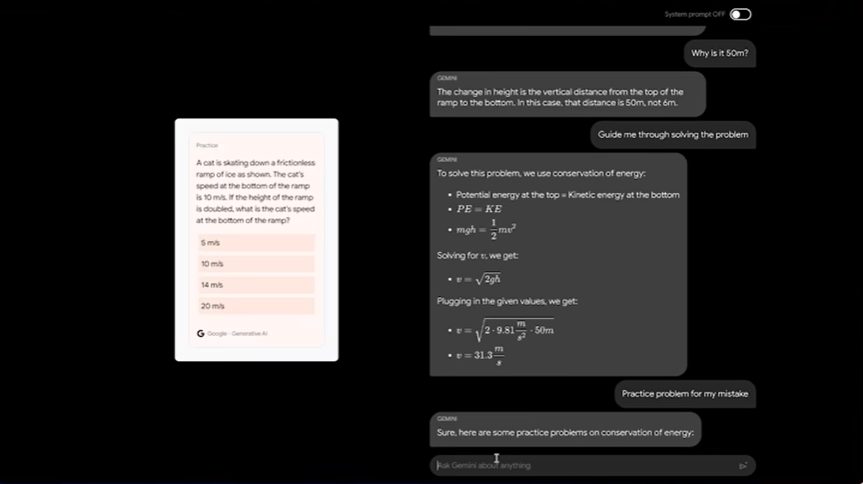
動画にはありませんが、Googleの技術レポートによると、Geminiは図やグラフの理解に高い性能を発揮することができ、例えば、棒グラフを読み取ってクロス集計表を生成する、といったことも可能だとされています。
MMLUやMMMUのベンチマークで好成績を記録したことを裏付けるような内容となっており、動画では物理学の問題が取り上げられていますが、法律や数学など様々な分野の問題に対しても同様に高いパフォーマンスが実現できるであろうことが予想されます。
詳しくは動画をご確認ください。
Gemini: Explaining reasoning in math and physics
発音指導や話者の識別
以下の動画では、Geminiによる音声データ処理の様子が紹介されています。Geminiは、音声データをテキストに変換してテキスト解析のモデルで処理するのではなく、ネイティブに音声データを扱えるように設計されています。そのため、動画内でデモンストレーションされているような、話者が話した外国語の発音について正しい発音を教えてくれたり、複数の話者が含まれる音声データであっても、話者を識別しながら処理を行うことができます。
Gemini: Processing and understanding raw audio
Geminiの利用シーン
発表されたばかりのGeminiですが、既にいくつかのサービスで利用可能となっています。ここでは、Geminiの利用方法と今後の展開予定について、現時点で発表されている情報を紹介します。
Bard
Googleのコンシューマー向け生成AIサービスであるBardにも、Geminiが展開されます。
これまで、Bardの生成AIモデルにはGoogleの「PaLM2」が用いられていましたが、本記事公開時点で、既にGemini Proが動作しており、BardでGeminiを利用することができます。しかし、まだ英語版かつテキストデータのみに限られた対応となっており、多言語化、マルチモーダル化は順次拡大予定とアナウンスされていますので、日本語でGeminiの性能を体験できるのはまだ先になります。
また、2024年の初頭にはGemini最高のパフォーマンスを提供するGemini Ultraをバックエンドとする「Bard Advanced」がリリースされる予定となっています。Bard Advancedの価格など詳細情報は明らかになっていません。
Vertex AI
Google CloudのAI開発プラットフォームであるVertex AIのGenerative AI StudioでもGeminiが利用できるようになる予定です。
まずは、Gemini ProがVertex AI上でGemini APIとして、2023年12月13日から利用可能になるとアナウンスされています。これにより、現行の生成AIモデルであるPaLM2と同様にAPI経由でGeminiの基盤モデルを利用できるようになり、Geminiを利用したアプリケーション開発が行えるようになります。
Android OS
Googleのモバイル端末向けOSであるAndroidでも今後、Geminiが利用できるようになるとアナウンスがされています。
現在も、Google純正のスマートフォンシリーズである「Pixel」では、独自のオンデバイスAIを利用した軽量で高精度な文字起こし機能等が搭載されていますが、こうした機能は今後Gemini Nanoを使ったものに置き換えられていく予定です。
開発者のとっては、Google Pixel 8 Pro以降のAndroid 14で利用できるAI Coreを利用して、Gemini Nanoを利用した開発ができるようになると予定されており、こちらは早期プレビューの申請が必要です。
【Geminiのこれから】今後の展望
ここまで、Googleの新しい生成AIモデルであるGeminiについて、現時点で明らかになっている情報を紹介してきました。まだ広く利用できる状態にはなっていないですが、今後、Geminiの利用は次第に広がっていきます。
GoogleはYoutubeの動画やGoogle検索をはじめとした独自の膨大なデータを持っており、既に大規模に生成AIの活用を行っています。例えばGoogle検索の結果に生成AIの要約機能が加わったのは記憶に新しいアップデートです。これらが今後Geminiに置き換わっていきますが、より人間と直感的に対話できるマルチモーダルなモデルであるGeminiによって、これらのサービスのユーザーエクスペリエンスはさらに向上していくでしょう。
また、コンシューマー向けだけでなく、Google CloudのVertex AIといったエンタープライズ向けのプラットフォームでもGeminiが利用できるようになりますので、企業は自社のデータを保護しながらも最新の生成AIを用いたアプリケーション開発を行うことができ、企業の生産性に大きく貢献することになるでしょう。
執筆者紹介






















