近年、データ活用の推進による企業の成長が脚光を浴びる中で、実際にデータ分析を実施している企業も増え始めています。
そんな中、データガバナンスが行き届いていない状態でデータ分析を行ってしまうと、間違った分析になってしまう可能性があります。
その結果、分析結果が正しくなかったり、分析の精度が低かったり、またはデータマネジメントのコンプライアンス違反やデータ流出などのリスクも考えられます。
このようなデータの品質管理の課題への対策として、「データリネージ」という考え方が現在注目されています。
データリネージは、データの流れを可視化することで、データの品質を保証しながらデータを管理するという考え方です。
本記事では、データリネージでのデータ品質管理のメリットを主軸に、Google Cloud のデータマネジメントサービスである Dataplex の特徴や BigQuery で品質管理するポイントについて解説します。
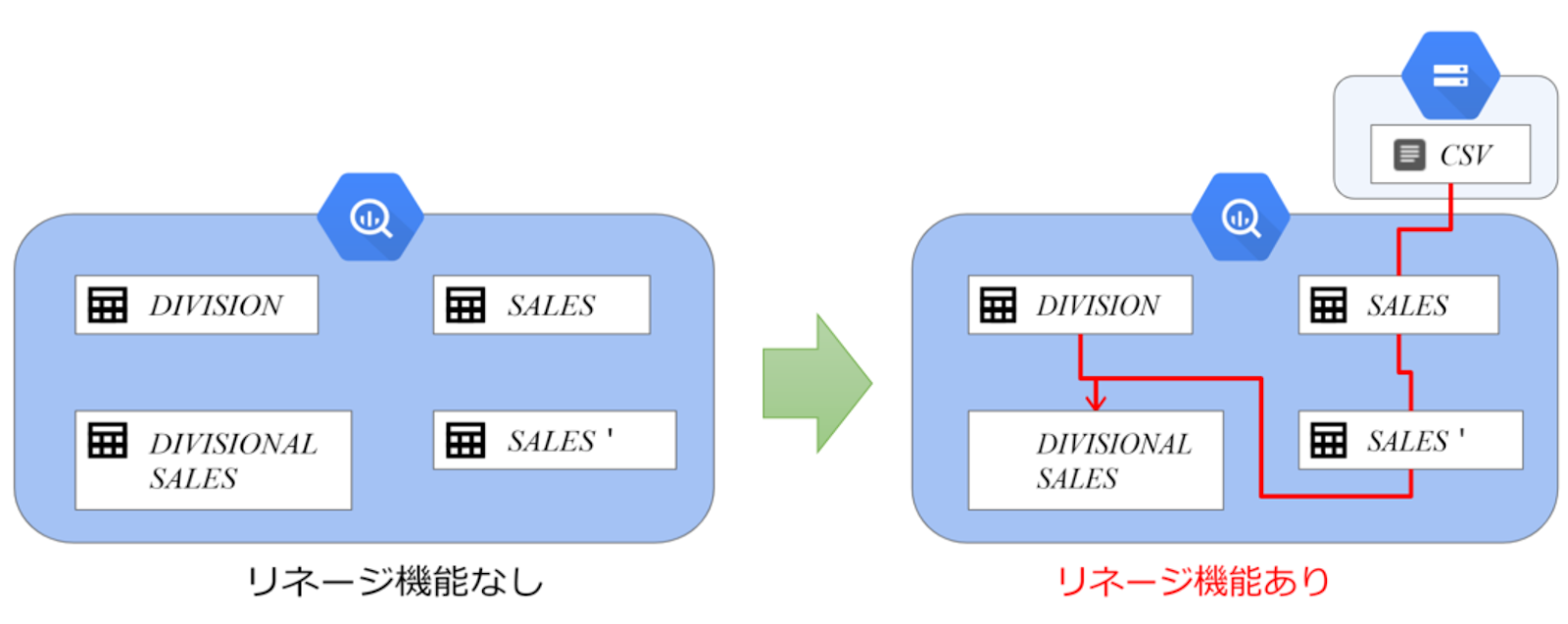
データリネージとはデータの流れを可視化する機能
データリネージ(Data Lineage)とは、直訳すると「データの系統」という意味です。データのライフサイクル(作成→活用)の流れを縦関係のつながりに見立てて、「いつ」「どこで」「どのように」取得されたデータなのかを把握することで、データの流れを可視化しデータが「正しい」ことを証明します。
また、データリネージの特徴として、メタデータを活用したデータマネジメントが挙げられます。メタデータとはデータに関するデータです。例えば、とあるファイルをデータと捉えると、そのファイルの名前、作成日時、格納場所、サイズなどのファイルに関する情報を保持しています。
効果的なデータ分析を行うためには、大量のデータを管理する必要があります。ですがデータが多ければ多いほど、ある1つのデータを調査、特定することが難しくなります。一方でメタデータが管理されている場合、メタデータの情報を基にデータを効率的に探索することができます。
このように、データおよびメタデータを管理しデータの流れを細かく把握することで、データソースを容易に追跡できるデータ分析基盤を構築するという考え方がデータリネージです。
データリネージのメリット5選
データリネージをベースとしたデータマネジメントが徹底されていることで、運用面での多くのメリットが生じます。
本章ではデータリネージを行うメリットについて5つご紹介します。
異常値・エラーへの対処が容易に
データ分析では、様々なデータソースから大量のデータを収集し、ETLで形式や型などを加工したデータを用意する必要があります。しかし、分析するデータに欠損があったりETLに誤りがあると、分析結果が正しくなかったり、分析が正しく実行されない場合があります。この時、データ数が多くETLでの処理が複雑であればあるほど元のデータの判別や異常箇所の特定が難しくなります。
データリネージによるデータマネジメントが行われている場合、このようなエラーでの対処が容易になります。データの流れが把握できるため、不正なデータがどの段階で作成されどの処理でエラー落ちしたのかが特定しやすくなります。また、異常値やエラーを自動で検出して取り除くように実装できれば原因特定する時間も省略できるためより正確な分析結果を導けます。
業績を向上させる
データリネージを行うと分析されたデータソースが正しいデータであり、分析結果も正確なものであるということを証明できます。
データ基盤の整備が不十分な場合、仮に分析結果の手段が正しくてもどのようなデータソースを用いて分析したのかデータをどのように加工したのかが不明瞭なままです。その結果、分析結果への信頼性が欠けてしまいます。
また、このような信頼度の高い分析結果を営業活動や社内での意思決定で提示できれば、ビジネスの効率が上がり業績も大きく向上することが見込めます。
コストを削減する
データ分析では大量のデータを扱うため、それらを管理する方法も重要になります。データリネージを行うことで、データの要不要を簡単に区別することができます。
必要なデータのみに絞り込むことができれば、不要なデータがストレージを占めることもありません。また、ETLなどの一連の処理も効率化できます。その結果、データの管理上のコストを削減することが期待できます。
リスクを回避する
データリネージを行うことで可視化されたデータの流れが把握できれば、データ漏洩や改ざんといったリスクがある箇所を特定し、不正を防止することも実現できます。
データ分析で大量のデータを扱う場合、意図しないデータが誤って引き出されてしまう恐れがあります。このような事態は企業の信用低下につながり、データ保護規則に違反するおそれも考えられます。そのため、データリネージでリスクを軽減し、データを安全に運用することが期待できます。
既存データパイプラインの活用
通常データ分析を行いたい場合、分析に使用するデータを抽出したり単位やカラム名を揃えるなど、実行する分析に適したETLを行うためのデータパイプラインを用意する必要があります。そのため、複数の分析結果を求めたい場合にはデータパイプラインも複数用意しなければなりません。
しかし、データリネージを行うことで、ETLでの加工処理によるデータの変化を管理することができます。ETLのどの処理でどのような加工を行っているかを可視化できれば、異なるパイプラインが必要な場合でも共通するETLを流用することが可能です。必要なETLのみ新たに構築することで、データパイプラインを構築する工数や構築後の管理コストを抑えることができます。
BigQuery 向けにデータリネージ システムを構築
Google Cloud は BigQuery というDWHサービスを提供しており、このサービスを利用してデータ分析を行うことができます。BigQuery ではデータリネージ機能(BigQuery Data Lineage)を構築することができ、分析するデータの流れを簡単に追跡することができます。
本章では、BigQuery のデータリネージ機能についてご紹介します。
リネージの抽出システム
データリネージの抽出システムは、主に以下の2種類の構成方法があります。
BigQuery では、DataCatalog で管理するメタデータやSQLを用いてデータリネージを解析しているため、パッシブリネージシステムで構成されています。
| アクティブリネージ | パッシブリネージ | |
| 利点 | データの流れを常に最新の状態に保つことができる | データ処理のパフォーマンスに影響を与えない |
| 欠点 | データ処理のパフォーマンスに影響を与える場合がある | データの流れの最新性が保たれない場合がある |
データリネージの記録情報
BigQuery のデータリネージ機能を有効にすると、BigQuery で以下のジョブが実行された際にデータの情報が自動的に記録されます。
〇新規テーブルに対するジョブ
- COPY
- LOAD(Cloud Storageからデータをロードする)
- CREATE TABLE
- CREATE VIEW
- CREATE MATERIALIZED VIEW
〇既存テーブルに対するジョブ
- SELECT
- INSERT SELECT
- MERGE
- UPDATE
- DELETE
Dataplexとは?概要と特徴を紹介
ここまでデータリネージを使用することで『活用するデータの信頼性や安全性を証明できる』ということを解説しました。
Google Cloud において、データリネージは Dataplex のサービスの一部として提供されています。
本章では、包括的なデータファブリックサービスである Dataplex について解説します。
Dataplexとは
Dataplex とは、Google Cloud が提供するデータファブリックサービスです。Google Cloud 上に分散している様々なシステムやデータソースからデータを収集し、Dataplex に一元化をすることで効率的なデータマネジメントやデータ活用を実現できます。
Dataplex の主な機能は、データの収集、処理、分析、保存です。大量のデータを管理し、上述の機能を自動化して行うことでデータの信頼性や価値を高めることが実現できます。
Dataplex の仕組み
Dataplex は、以下の3つのサービスで構成されています。
| Dataplex Lake | 収集したデータを格納し、統合・管理する |
| Dataplex Dataflow | データパイプラインを使用して、格納したデータを処理する |
| Dataplex Data Catalog | 収集したデータのメタデータを収集・管理する |
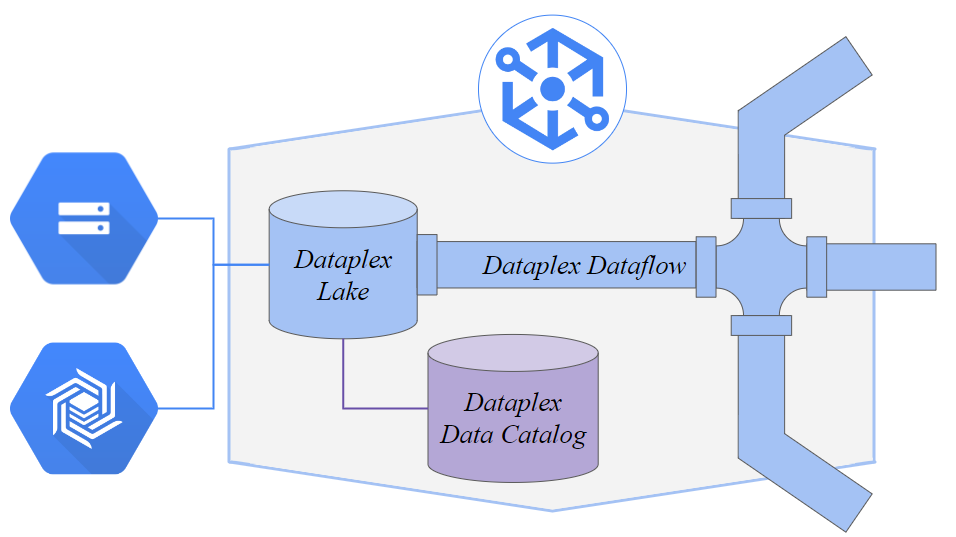
Dataplex は、Cloud Storage や Bigtable など、様々なデータソースからデータを収集できます。収集したデータは Dataplex Lake に書き込まれます。加えて、Dataplex Lake に格納したデータのメタデータは Dataplex Data Catalog に格納することができます。このようなメタデータを活用することで、データリネージも実行できます。
Dataplex Lake に格納されたデータは、Dataplex Dataflow を介して変換、フィルタリング、集計などの処理を行うことができます。処理されたデータは BigQuery でのデータ分析を中心に、Google Cloud の様々なサービスで活用することができます。
Dataplex を使用するメリット
データマネジメントで Dataplex を使用するメリットとして、データファブリックサービスである点が挙げられます。
データファブリック(Data Fabric)とは、様々なデータソースに分散されているデータを移動することなく1ヶ所に収集するデータマネジメント手法です。今までは「データは統一された基盤に移動して管理する」という考え方が主流でした。データファブリックサービスでは「データは散らばったまま、一元管理できる」ため、より多用途にデータを活用することができるようになっています。
また、このように一元管理されたデータを使用してデータ活用を行えるため、データの安全性を保つことができます。自動化による効率的なデータマネジメントができるため、管理上のコストや時間を削減することもできます。
さらに、Dataplex はデータの暗号化やモニタリング機能なども提供しているため、データの品質やセキュリティを強化することができます。
他にも、Dataplex はGoogle Cloud の他サービスとの親和性が高い点もメリットとして挙げられます。Dataplex は Google Cloud の他サービスにシームレスに接続することができるため、Dataplex Lake にデータを自動的に収集しデータを移動させずに統合して管理することが可能です。
BigQuery で Dataplex データ品質タスクを使用する3つのポイント
本章では、BigQuery で Dataplex のデータ品質タスクを使用する際の3つのポイントについて解説します。
BigQuery でのデータ品質タスクについて
Dataplex には、「データ品質タスク(Data Quality Task)」という機能があります。
この機能では、データの品質要件に関するルールを定義しておくことで、Google Cloud 上のデータを収集し定義したルールに基づいてデータ品質をチェックすることができます。また、ルールの品質基準を満たさないデータがある場合、データ品質エラーとしてレポートされます。
BigQuery のテーブルから収集したデータをこの機能を用いてチェックすることにより、BigQuery のデータ品質の向上が実現できます。
BigQuery で データ品質タスクを使用する方法については、公式ドキュメントをご覧ください。
Dataplex でデータ品質タスクを作成する(参照:Google Cloudガイドより)
Dataplex のデータ品質タスクの仕組み
データ品質タスクで定義できるデータ品質ルールは、以下の通りです。
| プロファイルに基づく推奨事項 | プロファイリングされた統計情報をルールとして定義できます。 ※このルールを定義するためには、事前にデータプロファイルスキャンを作成しておく必要があります。 |
| 組み込みルールの種類 |
Google Cloud に用意されているルールを定義できます。 |
| SQL 行チェックルール | SQLのSELECT文を使用して、行ごとに個別にルールを定義できます。 |
| SQL 集計チェックルール | SQLの集計関数を使用して、集計された値を用いたルールをテーブル全体に定義できます。使用するデータ分析ツールによってサービス内容は異なりますが、有料のツールであれば、セキュリティ面や機能面などでも法人に適したプランが提供されています。ビッグデータ分析を行ったり、部署を越えてツールを使用したい場合は、有料のツールの導入を検討しましょう。 |
上記以外にも、YAML ファイルを作成し仕様の構文に則ってデータ品質ルールを定義することで、ルールを自分でカスタマイズすることも可能です。
BigQuery で Dataplex データ品質タスクを使用するメリット
データ品質タスク機能を実装するメリットとして、自社の品質指標でデータを検証できる点が挙げられます。自社の品質水準でルールを作成してデータをチェックできるため、より効率的な品質管理を行えます。この機能もスケジュール化して自動でチェックできるため、無駄な時間やコストを裂くこともありません。
また、データ品質タスクはデータリネージと組み合わせることで、より高品質なデータマネジメントを実現することができます。この2つの機能の違いは、以下の通りです。
| データリネージ | データ品質タスク | |
| 目的 | データの流れを追跡すること | データの品質をチェックすること |
| 対象 | データ全体の流れ | データそのものの品質 |
したがって管理しているデータの品質をチェックしてデータの信頼性を上げ、そのデータを活用する際の流れを追跡して可視性を上げることで、データ品質の更なる向上を実現できます。
データ分析をするなら Google Cloud (GCP)がオススメ
ここまでBigQuery にデータリネージ機能とデータ品質タスク機能を組み合わせることで、「正しい」データを分析することができることについて解説してきました。これらは全て Google Cloud が提供するサービスの一部です。
Google Cloud は数あるクラウドサービスの中でも、特にデータ分析が得意です。Google が提供しているDWHである BigQuery は、膨大なデータを高速で処理することができます。
また、上記の品質管理機能以外にも機械学習や他GCPサービスなどと統合することも可能です。データを汎用的に活用できるため、サービス面、コスト面、パフォーマンス面、どの面においてもデータ分析をするには BigQuery がオススメです。
AWS提供のDWHである RedShift と比較した内容について知りたい方は、以下の記事が参考になります。
データリネージでビジネスの質を向上させる
今回はデータ分析におけるデータソースの管理や品質を効率化する機能である、データリネージおよび Dataplex データ品質タスクについて解説しました。
データリネージではデータの流れが、データ品質タスクではデータそのものの品質がそれぞれ明確になるため、経営者や事業部門に信頼できる正確なデータを届けることができます。そして、このような正確なデータを分析することでより説得力のある分析結果を提供できます。また、データソースが保証されているため、大規模なデータ分析もダイナミックにできます。
そのためにも、まずは規模の小さい段階から導入していき少しずつ規模を拡大しながらデータリネージを徹底させていく必要があります。
データ分析サービスが豊富な Google Cloud(GCP) を利用し、データリネージを導入することで効率的なデータ品質管理および効率的なデータ分析を実現させることができます。ぜひビジネス全体の質の底上げを目指してみてはいかがでしょうか。
株式会社電算システムでは、Google Cloud(GCP) の概要や特徴をまとめた資料を無料で提供しています。サービスを活用するには、記事で述べた情報以上に細かい知識が必要です。より多くの情報を集めたい場合は、ぜひ以下の資料をダウンロードしてみてください。






















