近年、ChatGPTを筆頭に様々な「生成系AI」が浸透し始めています。生成系AIはテキストや画像や音声などを自律的に生成してくれる技術であり、趣味や仕事など生活の様々な場面で利用されています。
そんな生成系AIの基盤技術として注目を集めている技術がLLM(大規模言語モデル/Large Language Models)です。
本記事では、LLMの仕組みをはじめ代表的なサービスや活用事例、LLMが現在抱える課題について解説します。
LLM(大規模言語モデル)とは機械学習の自然言語処理モデル
LLMとはNLP(自然言語処理モデル)の1つであり、人間が使用する言葉をコンピュータで処理する技術です。大量のデータとディープラーニング技術を用いて膨大な量のテキストデータを学習させることで、人間に近い流暢な会話が可能となり自然言語を用いた様々な処理を高精度で行います。
従来の自然言語処理モデルとの違いは、「計算量」「データ量」「モデルパラメータ数」の3要素を大幅に増加して構築されている、という点です。
- 計算量:LLMの学習に必要な計算リソースの量
計算量が多いほど、学習に必要な時間やリソースが減る。 - データ量:LLMの学習に使用するデータの量
データ量が多いほど多くのパターンを学習し、LLMの出力精度が上がる。 - モデルパラメータ数:LLMの学習モデルの複雑さを数値化したもの
モデルパラメータ数が多いほど複雑なパターンを学習し、LLMの表現力が増す。
また、LLMは現時点で以下の自然言語処理を行えます。
- 質問への回答
- 文章の生成、要約
- 機械翻訳
- 感情分析
- 画像の生成
- 音声の生成
最近では特にマルチモーダル化が進み、画像や音声など自然言語以外のデータも扱えるようになったためより多分野で活躍しています。
大規模言語モデル(LLM)の仕組み
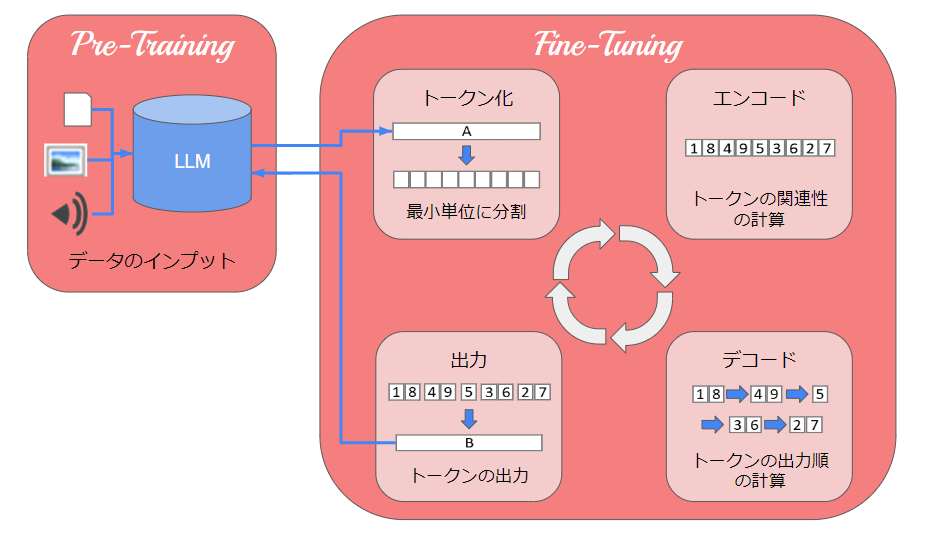
LLMが学習する流れですが、以下の2段階のプロセスが繰り返し行われます。
■事前学習(Pre-Training)
ニュース記事やブログ記事、小説など様々な種類のデータをインプットすることで、自然言語の構造や意味を学習します。
■微調整(Fine-Tuning)
テキストを生成・出力し、学習した自然言語で構造や意味を活用することで理解します。
微調整でテキストを出力する際、以下の処理を繰り返します。
- トークン化:入力されたテキストを単語や句などの最小単位(トークン)に分割する
- エンコード
a. トークンを数値に変換する(ベクトル化)
b. トークン間の関係を計算し、文脈を理解する
c. 文中のトークンの重要度を計算する - デコード
a. 2で計算したトークン間の関係をもとに、回答用のトークンを生成する
b. 生成した回答用トークンについて、最初に(次に)出力する確率を計算する - 出力:回答用トークンを確率の高い順に出力する
大規模言語モデル(LLM)を活用した代表的なサービス3選
LLMは、生成系AIを中心に様々なサービスに活用されています。
本章では、LLMを活用した代表的なサービスを3つ紹介します。
ChatGPT
ChatGPTは、OpenAIというAI専門の研究開発機関によって開発されたLLMベースのAIチャットサービスです。2022年11月に一般公開され、瞬く間に世界中で話題となった現在最も有名な生成系AIサービスの1つです。
ChatGPTは「GPT-3.5(Generative Pretrained Transformer)」というLLMがベースとなっています。質問への回答や文章生成をはじめ、幅広い内容にテキストで対応してくれます。
2023年3月から、「GPT-4」という新しいモデルがリリースされています。このモデルは従来のモデルに比べて出力精度や回答の整合性が向上し、より高度な推論や複雑な対応が可能となりました。
9月には「GPT-4V」と呼ばれる機能が実装され、画像アップロードが可能になりました。これにより画像内のテキストを抽出することや、画像生成エンジンを使った画像生成もできるようになりました。
また、5月には無償のiOSアプリでのリリースも開始されました。そのためより手軽にChatGPTを使えるようになってます。
ただし、最新モデルのGPT-4を使用するには有料プラン(ChatGPT Plus)に登録する必要があります。(月額20ドル)
Bing AI
Bing AIは、Microsoftが提供する検索エンジン「Bing」に搭載されたAIチャット機能です。2023年5月に一般公開されました。
Bing AIもChatGPTと同じ「GPT-4」というLLMがベースです。そのため、テキストから画像や音声など様々な種類のデータを学習しています。
Bing AIの最大の特徴は、検索エンジンと連携しているためリアルタイムの情報を踏まえた回答ができるという点です。回答内容には情報源のページURLも出力されるため、内容の事実確認も簡単に行うことができます。
また、GPT-4が無料で使えるため画像生成などのマルチモーダル機能も自由に使えます。
一方、1つの会話の回答数に制限があることやBing自体のシェアが低いことがこのサービスの課題です。
Bard
Bardは、Google AIによって開発された対話型AIサービスです。2023年4月に英語版がリリースされ、5月以降日本語にも対応しています。
Bardは、「PaLM 2(Pathways Language Model 2)」というLLMがベースです。こちらも多言語+多種類のデータを学習しており、人間の会話に近い言葉でのサービスを提供してくれます。
Bardの特徴は、Googleサービスと連携して豊富なサービスを提供できる点です。ただし、Chat GPTには備わっているAPIが実装されていないため、Google以外の外部のサービスとの連携はできません。
弊社電算ブログでも『Bard』を使い始めるまでの詳細や、利用方法についての解説を行っています。Bardの使い方について、ぜひチェックしてみてください。
企業におけるLLMの活用事例や身近な4例
前述のサービスを中心に、LLMを基盤としたサービスは多くの企業でも取り入れられており、業務効率化という点で役立っています。
本章では、実際にLLMを活用している企業での活用事例を4つ紹介します。
事例1.情報検索・情報の意味付けのサポート
LLMが最も得意とする分野は、情報検索領域です。
LLMは膨大な量のデータをインプットすることで、ユーザーの検索内容や検索意図を正確に理解し、より関連性の高い情報を検索して結果を表示することができます。
情報検索の活用例としては、検索エンジンやチャットボットなどが挙げられます。これらは幅広い質問に対して的確に回答することができるため、情報を手っ取り早く簡潔に知りたいという場面に最適です。
また、情報を意味付けして検索することも可能です。自然言語の構造や意味を理解することで、ユーザーにとって必要な情報だけを抽出することができます。
このような情報分類は、メール検索などに活用されています。例えば、LLMに「検索キーワード」をインプットすることでそのキーワードに関連する過去のメールから必要な情報のみを抽出し、情報を分かりやすく要約してくれます。
このように、情報検索にかかるコストの削減に貢献しています。
事例2.クリエイティブ制作や広告・マーケティングのサポート
クリエイティブ制作のようなゼロから何かを生み出す作業は、AIには難しいと考えられていました。しかし、LLMが創作物なども大量に学習することでコンテンツの特徴を把握しクリエイティブ制作の分野まで参入できるようになりました。
また、市場調査データを学習することでマーケティング戦略を洞察し、市場の分析を行うことにも役立っています。
活用例としては、LLMに「ターゲットとなる市場のデータ」をインプットし顧客のニーズや市場の変化、競合他社などを分析させることで効果的なマーケティング戦略を立案できます。そして立案した戦略をベースに、アイデアの生成から広告文や商品名の生成、商品のイメージ案やブランドロゴの生成まで幅広い創造力を発揮してくれます。
ただし、学習データが少ない分野では十分な活用は期待できません。あくまで人間の作業を補完するツールとして、クリエイティブな作業をより効率的により楽にするために活用してくことが求められています。
事例3.教育や学習のサポート
日本の教育機関での義務教育は、教師1人が多数の生徒に対して授業する形式で行われており、全員が同じペースで学んでいます。そのため、授業時間内に1人1人が個別で理解できなかったことやより深く知りたいことへの学習フォローが限られています。
教育分野でのLLMの活用例としては、LLMに各生徒の「学習状況」や「理解度・興味度」をインプットすることでその人に合う学習テキストやコンテンツ、指導方法を提供したり、必要に応じて補足説明や演習問題を提供することができます。
このように学習の個別最適化や知識獲得のサポートが実現することで、生徒の成績を向上させる効果があることも示されています。
また、LLMの活用は教師側にもメリットがあります。試験の採点や添削、成績管理など手作業で行っている業務をLLMに任せることで教師の業務が効率化され、より生徒と向き合える時間が増えることが期待されています。
事例4.オペレーション業務の効率化
LLMはオペレーション業務に活用できる場面も多く、大きな業務効率化が見込まれています。
例えばカスタマーサポートでの問い合わせ業務は、人間だけでは24時間365日対応することは難しいです。
LLMの活用法として多くの企業で実装されているサービスが「カスタマーサポートチャットボット」です。自然言語で理解し適切な回答ができるため、24時間365日迅速かつ正確に自動で応答してくれます。
その上、「消費者の問い合わせ内容」をインプットすることで顧客分析を行い顧客のニーズを把握して対応することも可能です。
またマニュアル業務でもLLMを活用することで、マニュアル作成や更新の工数削減や定型業務の効率化なども実現できます。
このようにLLMを活用することで顧客満足度の向上だけでなく、生産性と収益力の向上も期待されています。
大規模言語モデル(LLM)の6つの課題
現在様々なサービス展開に向けての開発が進められているLLMですが、いくつか課題も抱えています。
本章ではLLMが抱える現状の主な6つの課題について紹介します。
出力精度がモデルに依存する
LLMの出力精度は、採用する言語モデルによって大きく変化すると考えられています。
例えばGoogleの「Bard」ですが、初期は「LaMDA(Language Models for Dialogue Applications)」というLLMで開発されました。LaMDAはチャットボットのような会話型アプリケーションに特化したモデルであり、テキストとコードのデータで学習されてきました。
しかし新しいLLMである「Palm2」がリリースされて以降、BardのベースとしてPalm2が使われるようになりました。こちらはテキストとコードだけでなく画像や音声のデータも学習しており、学習アルゴリズムも改良されています。そのため、創作や翻訳などより幅広い用途で利用できるようになり、さらに自然な日本語で応答できるようにもなっています。
このように言語モデルは精度に大きく影響するため、開発する際のモデル選びは慎重に考える必要があります。
虚偽を起こす危険性がある
LLMが誤情報を生成してしまう現象を「ハルシネーション(Hallucination)」といいます。LLMの学習データに偏りがある、学習データが少ない事件や事実に対する質問である人間の入力情報に誤りがあるといった場合、ハルシネーションを起こす恐れがあります。
今後LLMが進化していくにつれハルシネーションの頻度や影響は減っていくことが予想されますが、LLMの特性上、完全に防止することは難しいとも考えられています。
ユーザーもハルシネーションの可能性を念頭に置き、利用方法や注意点を理解した上で使用する必要があります。
敵対的プロンプトへの対策が不十分
「敵対的なプロンプト」とは、機械学習モデルに意図しない出力を生成させるために設計された入力データです。LLMは敵対的プロンプトにより、攻撃的・差別的なテキストや誤ったテキストなどの有害な文章が生成されたり、モデルの性能低下や機能不全が発生する恐れがあります。
また、敵対的プロンプトは機械学習モデルの弱点を悪用して生成されます。そのため、敵対的プロンプトへの対策は日々講じられています。機械学習モデルの性能が向上すれば、より精巧な敵対的プロンプトが生成される可能性があるためこちらも完全に防止することは難しいでしょう。
機密情報が引き出される可能性がある
ユーザーが個人情報や企業秘密などの機密情報をLLMに誤って入力してしまった場合、LLMが機密情報を抽出する機能を悪用されたり、悪意のあるプロンプトを入力されることで、機密情報が漏洩する恐れがあります。
この対策としては機密情報を含むテキストの入力を禁止したり、特定の話題にしか回答しない、回答に差別的な内容が含まれる場合はストップするなどモデルの出力内容を制御する手法が挙げられます。
また、LLMの出力を制御する方法として「ガードレール」と呼ばれる考え方があります。これを導入すると特定の質問に対する回答アクションを定義することができるため、悪意ある質問を回避することが可能です。
学習データの偏り
学習データの構成や収集方法、処理方法によっては、学習データの偏りが発生してしまう恐れがあります。学習データの偏りがあると、誤った情報や差別的な言語が生成される危険性があります。
現在、学習データの偏りを防ぐための取り組みとして偏りを検出したり、補正する技術などの研究が進められています。
しかし、抽出する分野によってはバイアスがかかってしまうリスクにも注意する必要があります。
膨大な計算コスト
LLMの学習には膨大な量のデータの学習を反復して行う必要があり、その計算には大量のリソースを割り当てなければなりません。
そのため、初期設備の段階で大量の十分なリソースを割り当てられるほどの高価な機材を導入する必要があります。
リソースが不十分だと学習に時間がかかってしまい、LLMのパフォーマンス低下につながります。
対策としてはハードウェアの性能向上や計算アルゴリズムの効率化を実施し、学習処理を短縮することなどが考えられています。
またLLMの学習には膨大なコストがかかりますが、学習済みのモデルを動かすのみであれば少ないリソースで行うことができます。学習リソースと使用リソースを上手く使い分けることができれば、コストを抑えながら活用することもできます。
まとめ
LLMとは、大量のテキストデータの学習を行い、自然言語での処理を自動化する技術です。生成系AIの仕組みとして利用されていて、今では情報収集やクリエイティブ制作、マーケティングや教育事業など様々な分野で活用されています。
今後もLLM技術が進化することで現在できることの精度がより高くなり、より幅広い分野で活用されてより効率的な生活を送れるようになることが期待されています。
しかし、LLMはまだまだ発展途上の技術です。進化の陰に潜む弱点を狙われたり、悪用や間違った使われ方をされるなど危険やリスクも存在しています。
そのため、そのようなリスクを対策するのはもちろん、ユーザーにもLLMのリスクを認識した上で注意して適切な使い方をするように啓発していく必要があります。
本記事を読んでLLMに興味を持ち、AIへの更なる学びへの参考になれば幸いです。
また、LLMはGoogle Cloudと組み合わせることでより大きな効果を得られます。
Google Cloud(GCP)はGoogleがクラウドを介して提供しているサービスの集合体で、数多くのクラウドサービスの中でも特にAI/MLの分野に長けています。そのため、自然言語処理サービスや機械学習サービスなどLLM構築に必要なサービスが揃っています。
また、Google Cloudは必要な計算リソースをオンデマンドで提供することができるため機材などの初期投資も抑えることができます。
電算システムでは、Google Cloud(GCP)の概要や特徴をまとめた資料を無料で提供しています。サービスを活用するには、記事で述べた情報以上に細かい知識が必要です。より多くの情報を集めたい場合は、ぜひ以下の資料をダウンロードしてみてください。
資料ダウンロード
























