前回の記事(https://www.dsk-cloud.com/blog/gc/what-is-a-relational-database)では、RDBの基本構造やACID特性といった「データベースの標準」について解説しました。しかし、いざ実務で大規模なシステムを運用し始めると、教科書通りの知識だけでは太刀打ちできない壁に直面します。
「インデックスを貼っているはずなのにクエリが遅い」「アクセス急増時にデータベースがボトルネックになり、スケールアウトができない」「トランザクションの分離レベルを誤解してデータの不整合が起きた」……。これらは、多くのエンジニアが一度は経験する「RDBの洗礼」です。
本記事では、一歩踏み込んだエンジニア向けの実践編として、パフォーマンスを最大化する実行計画の読み方やスケーラビリティの確保手法、さらにはCloud SpannerやAlloyDBといった最新のクラウドRDBが従来の課題をどう解決しているのかを深掘りします。理論の先にある、実戦で勝つためのデータベース戦略を一緒に見ていきましょう。
パフォーマンスとスケーラビリティ
RDBが「表形式でデータを管理する」という基本を理解した次のステップは、いかにそのパフォーマンスを引き出し、システムの成長に合わせてスケールさせるかを知ることです。どれほど完璧なデータ構造を設計しても、適切なチューニングなしには、データ量の増加とともにシステムは必ず牙を剥きます。本章では、RDBを快適に使い続けるための「攻め」の技術であるパフォーマンス改善(インデックス、クエリ最適化)と、物理的な限界を突破するためのスケーリング戦略(垂直分割、水平分割)を解説します。
インデックス
インデックスは、膨大なデータから目的の行を高速に見つけ出すための「目次」です。RDBのパフォーマンス改善において、最も即効性があり重要な要素といえます。
多くのRDBで採用されているのがB-Tree(Balanced Tree)構造です。これはデータを木構造で保持し、ルートからリーフ(末端)まで常に一定の深さを保つ仕組みです。 検索時は全ての行を上から順に探す「フルテーブルスキャン」ではなく、木を辿ることで、データ量が増大しても計算量を最小限に抑え、極めて安定した高速検索を実現します(計算量は O(log n) と表されます)。
図で表すと以下のような形です。
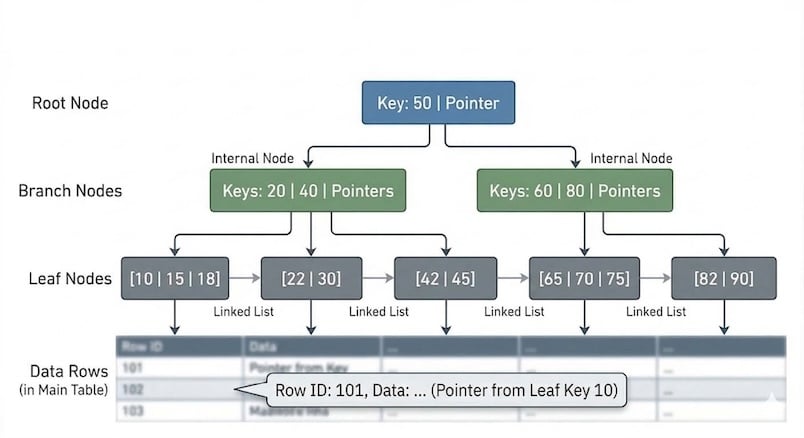
インデックスが有効なケースは、特定の値を指定する等価比較(=)や範囲検索(BETWEEN, <, >)、およびソート(ORDER BY)が発生するカラムです。特にカーディナリティ(値の種類・分散度)が高いカラムに付与すると、検索対象を劇的に絞り込めるため効果的です。
一方で、以下のような「インデックスが効かない(または避けるべき)」ケースには注意が必要です。
- 演算・関数を使用している: WHERE YEAR(date) = 2026 のように左辺のカラムを加工すると、構造上インデックスを利用できません。
- 中間一致・後方一致の LIKE 検索: LIKE '%word' は、木の左側から順に探索するB-Treeの特性上、フルスキャンが発生します。
- 更新頻度が極めて高い: データ更新のたびにインデックスの再構築(木のバランス調整)が発生するため、書き込み負荷がオーバーヘッドとなります。
クエリ最適化(実行計画の読み方)
データベースがSQLを受け取ると、内部の「オプティマイザ」が統計情報に基づき、最も効率的と思われる処理手順(実行計画)を自動で作成します。しかし、データ量の増加や偏りによって、オプティマイザが常に最善の道を選ぶとは限りません。そのためエンジニアは、意図通りにインデックスが使われているかを「実行計画」によって検証する必要があります。
確認方法は、対象となるSQL文の先頭に EXPLAIN (PostgreSQLでは実際の実行時間を測定する EXPLAIN ANALYZE が推奨)を付与して実行します。 出力結果で特に注目すべき項目は以下の通りです
- Type / Access Method(アクセスタイプ)
- const / eq_ref:主キーなどによる1行検索。理想的な速度です。
- index / range:インデックスの一部または範囲を利用。良好な状態です。
- ALL (Full Table Scan):最悪のケース。全行を読み取っており、大規模データでは致命的な遅延に繋がるため改善が急務です。
- Rows / Cost: 読み取る必要があると推定される行数や計算コスト。ここが異常に高い場合は、クエリの書き換えやインデックスの見直しが必要です。
- Extra / Filtered: Using filesort(メモリ外でのソート)や Using temporary(一時テーブルの作成)は、リソースを大量消費する「パフォーマンス劣化のサイン」です。
実行計画を読み解くことで、「なぜ遅いのか」という推測を「どのステップで詰まっているのか」という確信に変え、的確なチューニングが可能になります。
垂直分割と水平分割(シャーディング)
単一のデータベースサーバーで性能が限界に達した場合、スペックを上げる「スケールアップ」には費用やハードウェアの天井があります。そこで検討するのが、サーバーを増やして負荷を分散する「スケールアウト」の手法です。
垂直分割(Vertical Partitioning): テーブルのカラム単位や機能(マイクロサービス)単位でデータベースを分離する方法です。例えば「ユーザー基本情報」と、更新頻度の高い「アクセスログ」や「巨大なバイナリデータ」を別DBに分けることで、I/O負荷を分散します。
水平分割(シャーディング/Sharding): 同一構造のテーブルを、特定のキー(シャードキー)に基づき、複数のサーバーに分散保持する手法です。
シャーディングを採用するタイミングは、単一の書き込み(Write)負荷が限界に達し、読み取り専用の「リードレプリカ」増設だけでは対応できなくなったフェーズです。
主なメリットとデメリット
- メリット: ストレージ容量とスループットを理論上無限に拡張でき、単一障害点(SPOF)の影響範囲を限定できます。
- デメリット: アプリケーション側のロジックが極めて複雑になります。複数シャードを跨ぐ結合(JOIN)や一貫性を保ったトランザクションが困難になり、データの偏り(ホットスポット)が生じると特定のサーバーに負荷が集中するリスクがあります。
安易な導入は運用コストを激増させるため、まずはクエリ最適化や垂直分割を尽くし、最終手段として検討するのが定石です。
トランザクションと一貫性の深掘り
RDBの最大の強みは、ACID特性によってデータの整合性が厳格に守られていることです。しかし、これまで解説したパフォーマンス向上(スケーラビリティ)を追求するほど、この一貫性の維持は技術的に難しくなっていきます。「速度は出ているが、たまにデータが不整合になるシステム」は、ビジネスにおいて致命的なリスクを孕みます。本章では、高負荷な環境下でもデータの正しさを死守するための、トランザクションとロックの深い仕組みを紐解いていきます。
トランザクション分離レベル(Isolation Levels)
RDBのACID特性における「I(Isolation:分離性)」は、複数の処理が並行して動いても、あたかも一つずつ順番に実行されたかのように振る舞う性質です。しかし、厳格に順序を守ると並列性が失われ処理速度が著しく低下するため、SQL標準では4つの「分離レベル」によるトレードオフが定義されています。
エンジニアがまず理解すべきは、分離レベルが低いときに発生する3つの異常現象です。
- ダーティリード: 他のトランザクションがコミットする前の「書き換え中」のデータを読んでしまう。
- 非再現リード(Fuzzy Read): 同一処理内で2回同じ行を読んだ際、その間に他者が更新・コミットしたことで値が変わってしまう。
- ファントムリード: 範囲検索をした際、他者が行を追加・削除したことで、2回目に読み込んだ際に行数が増減している。
これらに対し、以下の4段階で制御を行います。
- READ UNCOMMITTED: ほぼ全ての異常を許容。整合性が保証されないため、実務での採用は稀です。
- READ COMMITTED: PostgreSQLやOracleのデフォルト。コミット済みの値のみを読みますが、非再現リードは防げません。
- REPEATABLE READ: MySQL (InnoDB) のデフォルト。一度読んだデータは保護されます。MySQLではMVCC(多版型同時実行制御)により、このレベルでもファントムリードを実質的に防いでいるのが大きな特徴です。
- SERIALIZABLE: 最も厳格。全ての異常を防ぎますが、ロック競合によるパフォーマンス低下が激しくなります。
実務上の落とし穴は、この「デフォルト設定への過信」です。 例えば在庫確認後の更新処理では、READ COMMITTED 下では確認直後に他者が在庫を減らす「割り込み」を許してしまいます。 整合性がクリティカルな箇所では、分離レベルを上げる検討のほか、次節で述べる「明示的なロック」の活用が不可欠です。
各分離レベルと、それによって防止できる異常現象の関係を整理すると以下の通りです。一貫性とスループットはトレードオフの関係にあるため、システム要件に応じた最適なレベルの選択が求められます。
| 分離レベル | ダーティリード | 非再現リード | ファントムリード |
| READ UNCOMMITTED | 発生 | 発生 | 発生 |
| READ COMMITTED | 発生しない | 発生 | 発生 |
| REPEATABLE READ | 発生しない | 発生しない | 発生 |
| SERIALIZABLE | 発生しない | 発生しない | 発生しない |
ロックの仕組み
データベースにおけるロックとは、特定のデータ(行やテーブル)に対して、複数のトランザクションが同時に更新を行わないよう、操作権限を制限する仕組みです。
主に使われるのは、以下の2種類のロックです。
- 共有ロック(Sロック): 「読み取り」のためのロック。他者が同時に読み取ることは許可しますが、その間 の更新は禁止します。
- 排他ロック(Xロック): 「更新」のためのロック。他者による読み取りも書き込みも一切禁止し、データの整合性を担保します。
これらを適切に制御しないと発生するのがデッドロックです。 これは、2つのトランザクションが互いに相手の持つロックの解放を待ち続け、処理が永久に停止する状態です。
デッドロック回避の鉄則
- 更新順序を統一する: 全ての処理で「テーブルA → B」の順でアクセスするようルール化すれば、逆順による待ち合いを防げます。
- トランザクションを短く保つ: ロックの保持時間を最小限にし、競合確率を下げます。
- 適切なロック粒度を選択する: 可能な限り「テーブル単位」ではなく「行単位(Row Lock)」でロックし、他処理への影響を最小化します。
最新のクラウドRDBトレンドへの橋渡し
ここまで、RDBのパフォーマンスと一貫性を支える内部構造について深く掘り下げてきました。しかし実務においては、こうした「仕組み」を理解した上で、いかに運用のオーバーヘッドを減らし、サービス成長に集中できる基盤を選ぶかが鍵となります。本章では、これまでの課題を鮮やかに解決する最新のクラウドRDBの選択肢を、Google Cloudのサービスを例に解説します。
Cloud SQL(フルマネージドな標準RDB)
Cloud SQLは、MySQLやPostgreSQL、SQL Serverとの高い互換性を持つフルマネージドサービスです。最大の利点は、既存のアプリケーション資産やエンジニアのスキルをそのまま活かせる点にあります。バックアップやパッチ適用などの運用負荷を最小限に抑えつつ、リードレプリカによる読み取り負荷の分散も容易です。ただし、書き込み負荷に対するスケーリングは、インスタンスのスペックアップ(垂直スケーリング)に依存するという、伝統的なRDB特有の限界も併せ持っています。
Cloud Spanner(究極の水平スケーリング)
Cloud Spannerは、世界規模での水平スケーリングを可能にしながら、ACID特性(強一貫性)を完全に維持する唯一無二のデータベースです。従来のRDBでは「整合性を保つなら単一サーバー、スケールするなら一貫性を犠牲にする(NoSQL)」というトレードオフが常識でしたが、Spannerはその常識を覆しました。分散システムの複雑さを隠蔽し、ダウンタイムなしで無限の拡張性を提供できるのが最大の真価です。
AlloyDB(サーバーレス的な次世代RDB)
Cloud SQL以上の性能と、Spannerほどのコスト・特殊性を必要としないケースで有力な選択肢となるのがAlloyDBです。PostgreSQL互換を維持しつつ、ストレージと演算リソースを分離したアーキテクチャを採用しています。これにより、標準的なPostgreSQL比でトランザクション処理は最大4倍、分析クエリは最大100倍という高速化を実現しました。読み取り負荷に応じた柔軟なスケーリングやAIによる自動最適化など、サーバーレス的な利便性も備えています。
Cloud SQL、Spanner、AlloyDBの使い分け
これらのサービスは、データの規模と成長予測、そして許容できるコストや運用要件によって使い分けます。
- Cloud SQL: 既存アプリの移行や、データ量が数TB程度までの一般的なWebサービスに最適。
- Cloud Spanner: 数十TB超の膨大なデータ、グローバル展開、ミッションクリティカルな金融系・大規 模ゲーム等に最適。
- AlloyDB: 「Cloud SQLでは性能が足りないが、PostgreSQLの機能や互換性は100%維持したい」というモダンなエンタープライズ用途に最適。
それぞれのサービスが持つ特性を整理すると、以下の表のようになります。プロジェクトの要件や将来的なデータ成長予測に照らし合わせ、最適なデータベース選定の参考にしてください。
| サービス名 | 主な特徴 | 最適なユースケース | 拡張性の方向 |
| Cloud SQL | 高い互換性を持つ標準的なフルマネージドRDB | 既存アプリの移行、数TB程度の一般的なWebサービス | 垂直スケーリング(スペックアップ)中心 |
| Cloud Spanner | 無限の拡張性と強一貫性を両立した分散DB | 数十TB超の膨大なデータ、グローバル展開、金融・大規模ゲーム | 水平スケーリング(ノード追加) |
| AlloyDB | PostgreSQL完全互換で標準比最大4〜100倍の高速性能 | Cloud SQLでは性能が不足するが、PostgreSQLの機能を維持したいエンタープライズ用途 | サーバーレス的な柔軟なスケーリング |
次世代のデータベース設計をリードするエンジニアへ
RDBは、インデックスや実行計画といった内部構造への深い理解があってこそ、その真価を発揮します。単に「動く」クエリを書くフェーズを卒業し、ACID特性とパフォーマンスのトレードオフを制御できるようになれば、システム設計の幅は劇的に広がります。
さらに、Cloud SpannerやAlloyDBといった最新技術は、私たちが長年悩まされてきた物理的な制約すら書き換えようとしています。基礎を疎かにせず、常に進化するクラウドネイティブな選択肢をキャッチアップし続けることが、モダンなエンジニアに求められる最も重要な資質です。
執筆者紹介
























